0. 写在前面
MakeGKDInspectBetter,或者说更熟悉的:GKD网页审查工具增强脚本,
是一个提高GKD网页审查工具使用体验的用户脚本。
它可以被绝大多数的用户脚本加载器加载,包括但不限于:TemperMonkey、ScriptCat。
其最初版本诞生于2024年3月3日,彼时它的名字仍然叫做:GKD网页审查工具复制增强。
这篇博文,主要总结下该脚本的发展历程,以及部分代码的讲解。
该脚本的发展历程,我觉得可以分为三个阶段:按钮监听阶段、复制监听阶段以及大杂烩阶段。
1. 发展历程
1.1 按钮监听阶段
得益于Greasyfork的更新记录,我们得已看到最初版的脚本是怎么样的:
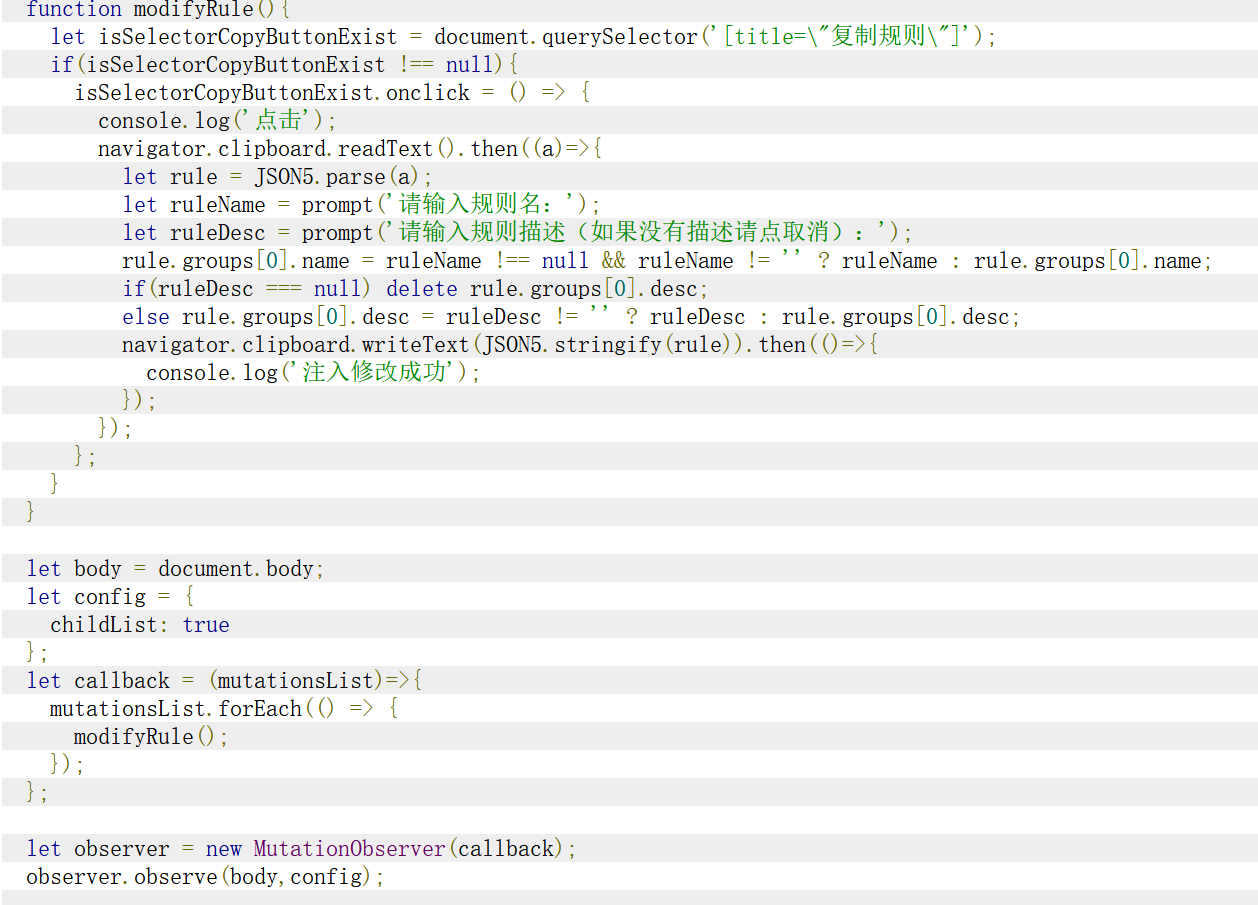
可以看到,初代脚本通过MutationObserver去检测复制按钮是否出现并监听其点击事件去显示菜单,
功能也只有修改规则名称和描述。
那么为什么需要去检测按钮是否出现呢?
是因为GKD网页审查工具使用Vue去编写,DOM元素并不是进入网页就加载的。
在3月3日和3月4日进行了多次的迭代,使用layui美化了界面,
同时对监听按钮事件的方法进行了一次迭代:

可以看到,在1.0.0版本使用了document.onreadystatechange。
在这个版本中,给每个复制按钮附加了点击事件,去弹出菜单。
后续的这方面的修改基本都是这两种方法的混合使用,和缝缝补补,在此不作赘述。
1.2 复制监听阶段
该阶段开始于4月24日更新的1.5.0版本:
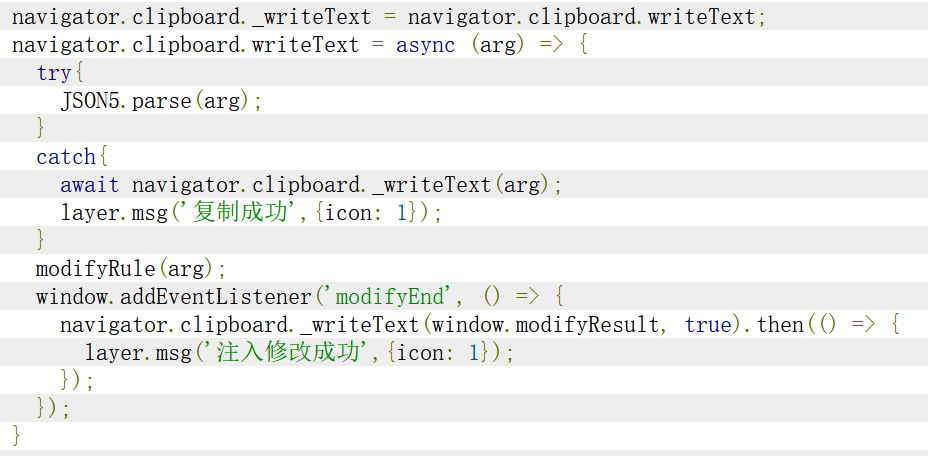
可以看到,这时候已经使用了覆写函数的方式去实现复制的监听。
通过查看GKD网页审查工具的源代码可知,复制使用的是navigator.clipboard.writeText函数,
所以我们通过覆写该函数就可以实现复制的监听,从而摆脱低效的DOM节点监听。
事实上,直到如今依然使用的是复制监听的方法。
只不过,从8月2日提交的1.6.4版本,将原来的覆写函数方式,修改为了更优雅的写法:Proxy与Reflect的配合写法:

使用Proxy代理navigator.clipboard.writeText函数,
使用Reflect在Proxy内调用navigator.clipboard.writeText函数。
之后不久,使用由GKD开发者@lisonge的一个Vite插件,使用Vue去重构了整个插件,将所有代码开源至Github,使用mdui重写UI界面。
1.3 大杂烩阶段
从理论来讲,这一阶段其实属于复制监听阶段,但我还是将其独立出来,作为一个新的阶段。
该阶段开始于8月29日。
当时,除了这个脚本之外,我还另外维护了两个脚本:GKD网页审查工具规则快捷搜索和GKD网页审查工具自动showSize。
在8月29日,将GKD网页审查工具规则快捷搜索脚本整合进了GKD网页审查工具复制增强脚本中,
也是从这时起,这个脚本改名成了:GKD网页审查工具增强。
正是这一次的整合,才被我称为大杂烩,也是我将其独立作为一个阶段的原因:将其他的增强性脚本统一进了一个脚本中。
这是一个全新的阶段,这个阶段的版本迭代中,不断开拓出了新的增强方式,这将在下节的代码讲解中一并提到。
2. 代码讲解
2.1 activityIds规则复制优化
为什么要讲这个?
因为这是脚本第一次涉及indexedDB内的数据。
这是其具体的实现代码:
export const simplyActivityIds = async (
snapshotId: string,
): Promise<string | false> => {
const snapshotInfo = await snapshotStorage.getItem<Snapshot>(snapshotId);
const activityId = snapshotInfo?.activityId;
if (activityId) {
const appId = snapshotInfo.appId;
if (activityId.startsWith(appId) && activityId[appId.length] === '.') {
const simplyActivityIds = activityId.replace(appId, '');
return simplyActivityIds;
} else return false;
} else return false;
};可以看到这一句:
const snapshotInfo = await snapshotStorage.getItem<Snapshot>(snapshotId);这是在读取网页审查工具存储的快照信息。
整段代码主要的作用就是:判断activityId的开头是否与appId相同,若相同,则返回去除相同部分的activityId;若不相同,则返回完整的activityId。
那么有人要问了,if内直接调用startsWith方法不就可以了吗?
为什么还要加上一句
activityId[appId.length] === '.'举个例子就明白了。
例如现在有一个软件,包名是test.example.com,
它分别有activityId为test.example.com.Main和test.example.com123.Share的页面,
如果使用startsWith方法,那么两者判断都为true,
那么最后返回的结果就是:.Main和123.Share。
这很显然出现了问题,所以才要加上这个判断,
确保包名后接的是分隔符.,才返回true。
由此开始,基于修改indexedDB数据的节点隐私打码功能上线了。
2.2 节点隐私打码
这段代码比较复杂,所以仅节选部分作为展示、讲解。
这是其核心实现代码:
interface EditNodeOption {
target: AttrList;
value: PrimitiveType;
};
export const editNode = async (
snapshotId: string,
nodeId: number,
options: EditNodeOption[],
): Promise<boolean> => {
try {
const snapshotInfo = await snapshotStorage.getItem<Snapshot>(snapshotId);
const nodes = snapshotInfo!.nodes;
const nodeAttr = nodes[nodeId].attr;
options.forEach(
(option) => ((nodeAttr[option.target] as PrimitiveType) = option.value),
);
nodes[nodeId].attr = nodeAttr;
snapshotInfo!.nodes = nodes;
await snapshotStorage.setItem(snapshotId, snapshotInfo);
return true;
} catch {
return false;
}
};通过给editNode函数传入要修改的节点id和要修改的节点信息,用传入的信息覆盖原本的节点信息,达到给节点打码的效果。
interface EditNodeOption {
target: AttrList;
value: PrimitiveType;
};此处的target为修改的属性,如:text、desc等;value则是属性的内容,需要符合target接受的类型。
2.3 坐标生成
2.3.1 背景
这部分内容是该脚本以及我第一次使用canvas的实验,具有一定的意义。
先讲讲为什么我们需要这个功能。
在2024年,相对坐标点击刚出现的那会儿,相对坐标是要人工计算的。
@AIsouler总结出了计算公式,但是由于Q群炸了,Github提交历史也太过久远,就不放截图了。
后来虽然网页审查工具也上线了相对坐标和绝对坐标的查看,但是计算依旧要人工进行。
这就是这个功能诞生的原因。
2.3.2 代码简释
这部分代码很长,所以分开来讲。
先看一下获取信息这部分的代码:
export const getInfo = async (): Promise<
[
HTMLCanvasElement,
number,
number,
number,
number,
number,
number,
HTMLImageElement,
]
> => {
const canvas = document.querySelector('#canvas')! as HTMLCanvasElement;
const snapshotId = getSnapshotId();
const screenshot = await getScreenshot(snapshotId);
const nodeId = getCurrentNodeId();
const screenWidth = (await getScreenInfo(getSnapshotId())).width;
const screenHeight = (await getScreenInfo(getSnapshotId())).height;
const left = (await getNodeAttr(snapshotId, nodeId, 'left')!) as number;
const top = (await getNodeAttr(snapshotId, nodeId, 'top')!) as number;
const width = (await getNodeAttr(snapshotId, nodeId, 'width')!) as number;
const height = (await getNodeAttr(snapshotId, nodeId, 'height')!) as number;
const fullImg = arrayBufferToImage(screenshot);
return [canvas, screenWidth, screenHeight, left, top, width, height, fullImg];
};这些都比较好懂,大部分都是用我自封装的函数去获取的快照内部,或者DOM节点信息,
所以这里只解释一个点:
const fullImg = arrayBufferToImage(screenshot);这里用来获取快照截图,网页审查工具使用ArrayBuffer存储截图信息,所以这里我使用自封装的函数将其转为HTMLImageElement,怎么转换具体自行搜索。
然后看一下双视图的实现:
export const partialView = (
canvas: HTMLCanvasElement,
screenWidth: number,
screenHeight: number,
left: number,
top: number,
width: number,
height: number,
fullImg: HTMLImageElement,
) => {
window.Hanashiro.currentPositionView = 'partial';
const ctx = canvas.getContext('2d')!;
const tampCanvas = document.createElement('canvas');
const tampCtx = tampCanvas.getContext('2d')!;
canvas.width = width;
canvas.height = height;
tampCanvas.width = screenWidth;
tampCanvas.height = screenHeight;
tampCtx.drawImage(fullImg, 0, 0, screenWidth, screenHeight);
const imgData = tampCtx.getImageData(left, top, width, height);
ctx.putImageData(imgData, 0, 0);
};
export const globalView = (
canvas: HTMLCanvasElement,
screenWidth: number,
screenHeight: number,
fullImg: HTMLImageElement,
) => {
window.Hanashiro.currentPositionView = 'global';
const ctx = canvas.getContext('2d')!;
canvas.width = screenWidth;
canvas.height = screenHeight;
ctx.drawImage(fullImg, 0, 0, screenWidth, screenHeight);
};全局视图(即globalView)没什么好说的,就是用传入的信息,然后整张图贴上去。
我们来看局部视图(partialView)。
首先是传入需要的信息,这不必多说,
window.Hanashiro.currentPositionView = 'partial';这句是储存当前视图模式。
我们看到,除了传入的canvas之外,还创建了一个tampCanvas(其实应该是,这是用来干什么的?tempCanvas,我脑瘫打错了,现在懒得改了)
局部视图,就是只展示节点对应部分的图片,这意味着我们需要对图片进行局部展示。
所以我们先用一个创建一个不展示到页面中的canvas,将整张图贴上去,
之后调用getImageData方法,将节点对应部分的图片给截下来,
然后再在对用户可见的canvas中把获取到的图片给画上去。
我们最后再来看坐标计算的代码:
export default async () => {
const [canvas, screenWidth, screenHeight, left, top, width, height, fullImg] =
await getInfo();
fullImg.onload = () =>
partialView(
canvas,
screenWidth,
screenHeight,
left,
top,
width,
height,
fullImg,
);
canvas.onclick = (e) => {
let x = e.offsetX,
y = e.offsetY;
if (window.Hanashiro.currentPositionView == 'global') {
x -= left;
y -= top;
}
const absolutePosition: Position = {
left: left + x,
top: top + y,
};
const relativePosition: Position = {
left: `width * ${String((x / width).toFixed(4))}`,
top: `width * ${String((y / width).toFixed(4))}`,
};
window.Hanashiro.nodePosition = {
absolute: absolutePosition,
relative: relativePosition,
};
const result = document.querySelector('#result')! as Dialog;
result.open = true;
};
};一开始默认使用局部视图,所以在获取到截图后就调用partialView函数。
通过获取canvas click事件的offsetX和offsetY,我们可以知道用户点击了canvas的哪个地方,从而计算其坐标。
由于在局部视图中,获取到的坐标需要通过分别加上节点的left和top属性来计算其绝对坐标,而在全局视图中不需要。
所以为了坐标计算的通用性,如果为全局视图,就先分别减去left和top属性,这样加回来之后,坐标就还是正确的。
if (window.Hanashiro.currentPositionView == 'global') {
x -= left;
y -= top;
}这就是这段代码的意义。
相对坐标的计算就是套@AIsouler的计算公式了。
总的而言,功能实现其实就这么点,但是由于我在开头说了,这是我第一次实践canvas,所以资料也查了很多,踩的坑也不少。
不过总算是把这个功能写出来了,也算是可喜可贺。
3. 写在最后
这篇文章仅作总结使用,代码的说明后续会挑选一些功能的代码继续更新。
如果有人对代码有更好的优化建议,也欢迎到Github仓库发起PR。
如果有人因此脚本有所启发,开发出更好用的脚本,那就再好不过了。


